 九游体育app官网
九游体育app官网
好意思国国度工程院外籍院士沈向洋(图片起首:IDEA)
11 月 22 日举行的 2024 年 IDEA 大会上,IDEA 考虑院创院理事长、好意思国国度工程院外籍院士沈向洋以"从期间突破到产业和会"为主题发饰演讲,其对东谈主工智能"三件套"(算力、算法、数据)的最新想考。
沈向洋指出,在期间大爆发时期开展编削,对期间的深度相识尤为进军。他认为,从算力来看,异日十年 AI 的发展可能需要增长 100 万倍的算力,远超摩尔定律预言的 100 倍增长,而英伟达成为了 AI 行业最了不得、最顺利的一家公司。
凭据 EPOCH AI 的数据,每年最新的大模子对算力的需求王人在以惊东谈主的速率增长,年均增长率高出四倍(400%)。适度面前,全球依然"烧掉"了高出 1000 万张 GPU 算力卡。
"英伟达硬生生把我方从我方从作念硬件、芯片的乙方变成了甲方,今天能拿得到英伟达的卡就不错说是顺利了一半。"沈向洋称,"讲(GPU)卡伤热枕,没卡没热枕。"
沈向洋现场知道,未来黄仁勋会到香港科技大学摄取荣誉博士学位的授予,而他准备面前和黄仁勋商议一些对于期间、指令力和创业的故事,非常是在针对算力发展的问题,探讨异日十年还会不会像当年十年那样能够达到 100 万倍的增长。
会后,沈向洋还向钛媒体 App 知道,Scaling Law(圭表定律)放缓的原因是 GPT-5 还没发布,背后主要与数据关系。
据悉,粤港澳大湾区数字经济考虑院(International Digital Economy Academy,简称" IDEA 考虑院")于 2020 年由微软公司原全球实施副总裁、好意思国国度工程院外籍院士沈向洋创建,是一家面向 AI 和数字经济产业和前沿科技的外欧化编削式考虑机构。
IDEA 考虑院致力于于 AI 和数字经济领域前沿考虑与产业落地。面前该院包括低空经济考虑中心、计较机视觉与机器东谈主考虑中心、AI 金融与深度学习考虑中心、基础软件中心、AI 安全普惠系统考虑中心等。
这次,IDEA 发布视觉、具身智能、合成数据、AI for Science、AI for Coding、低空经济等多个领域的新期间和新模子的前沿考虑与产业落地效劳,兑现 AI 从期间突破到产业和会。
视觉大模子:IDEA 团队本次大会发布了该系列最新的 DINO-X 通用视觉大模子,领有委果的物体级别相识武艺,兑现洞开全国(Open-world)宗旨检测,无需用户教唆,平直检测万物。在零样本评估设立中,DINO-X Pro 在业界公认的 LVIS-minival 数据集上取得了 59.7% 的 AP,在 LVIS-val 数据集上,DINO-X Pro 也施展亮眼,取得了 52.4% 的 AP。具体到 LVIS-minival 数据集上的各个长尾类别评估中,DINO-X Pro 在珍稀类别上取得了 63.3% 的 AP(比 Grounding DINO 1.5 Pro 还要高出 7.2%),在常见类别上取得了 61.7% 的 AP,在频繁类别上取得了 57.5% 的 AP。 行业平台架构:IDEA 团队还推出行业平台架构,通过一个大模子基座,结合通用识别期间结合,让模子不需从头覆按,就可边用边学,支握多种各样的 B 端愚弄需求。 具身智能:IDEA 考虑院这次便一连晓示三个讨好:与腾讯讨好,在深圳福田区、河套深港科技编削讨好区落地竖立福田实验室,聚焦东谈主居环境具身智能期间;与好意思团讨好,探索无东谈主机视觉智能期间;与比亚迪讨好,拓展工业化机器东谈主智能愚弄。 合成数据:IDEA 团队自研了语境图谱期间,处理过往文本数据合成决议的各样性匮乏等问题。该期间为合成数据引入"指导手册",以图谱为纲,指导用于合成的语境采样。实验收尾夸耀,IDEA 团队的决议能握续为大模子带来武艺升迁,施展高出面前的最好实际(SOTA);从 token 糜掷来看,平均简易资本 85.7%。面前,该期间内测平台已洞开,通过 API 提供干事。 AI for Science:在瞻望方面,IDEA 研发了多个化学领域行家大模子,分子属性瞻望和化学反应瞻望武艺均处业界源流水平;在数据方面,IDEA 蛊卦了化学文件多模态大模子,集中晶泰科技发布专利数据挖掘平台 PatSight,将药物领域的专利化合物数据挖掘时候,从数周裁减至 1 小时。 AI for Coding(编程言语):IDEA 考虑院的 MoonBit 团队展示了其蛊卦平台强盛的 AI for coding 体验。MoonBit 是专为云计较与角落计较遐想的 AI 云原生编程言语及用具链,已具备完备的多后端支握和跨平台武艺,可在硬件上平直运行,支握 RISC-V。MoonBit 的开源蛊卦平台,将于 12 月舒适洞开。 低空经济:IDEA 推出低空料理与干事操作系统 OpenSILAS 1.0 Alpha 版,还联袂 17 家产业伙伴发起 OpenSILAS 编削集中体,以及《低空经济白皮书 3.0》低空安全体系的发布等。
此外,IDEA 还展示包括学术大模子和 AI 科研神器 ReadPaper、营销创作大模子,以及面向经济与金融领域的经济大模子、运计议策大模子、投资大模子等多款新 AI 期间与家具。
沈向洋示意,在当年所有这个词广受接待的编程言语中,还莫得一个是由中国蛊卦者创造的,而如今,AI 时期也必将催生新的编程范式,中国蛊卦者将会起到错误作用。
" ChatGPT 展示了一种新的可能:当期间突破达到一定程度,不错跳过传统的家具商场匹配 ( PMF ) 流程,平直兑现期间商场匹配 ( TMF ) 。"沈向洋示意,如果 GPT-5 问世,按照其估量,可能需要 200T(200 万亿)界限的数据。
沈向洋强调,AI 正在改变科研神色。从"细目场所"(ARCH)到"选择课题"(Search),再到"深入考虑"(Research),每个要津王人将被重塑。今天 o1 不仅不错作念数据、作念编程,还不错作念物理、作念化学等。
"我以为接下来这几年,算法沿着 SRL(强化学习)这条谈路走下去,一定会有令东谈主惊艳的全新突破。"沈向洋示意。
(本文首发于钛媒体 App,作家|林志佳,裁剪|胡润峰)
以下是沈向洋演讲的主要内容,钛媒体 AGI 裁剪用心整理了其中精彩部分:
今天是 IDEA 考虑院在深圳举办的第四届 IDEA 大会。
转头发展历程,三年前的第一届大会上,IDEA 初次向公众展示了考虑院的责任效劳。在第二届大会上,咱们邀请了李泽湘教授、徐扬生教授、高文教授等学界翘楚进行深入对话。大家开打趣讲地咱们四个东谈主叫作念深圳 F4。
值得一提的是,这些学者王人是我 90 年代初赴好意思留学时最早沉稳的中国粹者。三十年后咱们能在深圳重聚,恰巧印证了深圳行动编削创业热土的特有魔力。
经过四年发展,IDEA 考虑院已发展成领有 7 个考虑中心、约 450 名职工的科研机构。咱们选择这些职工,双向选择的流程中咱们强调这样的理念,"科学家头脑、企业家修养、创业者精神"。来到深圳、来到福田、来到 IDEA 王人是想干一番奇迹。
当年几年,东谈主工智能的闹热发展让通盘行业充满憧憬和期待。在东谈主工智能发展进度中,"算力、算法、数据"这三件套恒久是中枢因素。接下来,我将从这三个方面,详备分享我方的不雅察和想考。
源流从算力提及。
行动计较机领域的从业者,咱们一直见证着通盘计较行业当年 40、50 年来算力的束缚升迁。早期有盛名的"摩尔定律",英特尔建议每 18 个月算力增长一倍。
但在当年十几年,跟着东谈主工智能,非常是深度学习的发展,对算力的需求呈现出前所未有的增长态势。
凭据 EPOCH AI 的数据,每年最新的大模子对算力的需求王人在以惊东谈主的速率增长,年均增长率高出四倍。
这个数字意味着什么?如果按照这个增长速率,十年间算力需求的增长将达到惊东谈主的 100 万倍。比拟之下,传统的摩尔定律下 18 个月翻一倍的增长,十年也不外是 100 倍的增长。
算力是错误,算力便是分娩力。为什么这样讲?当年十几年不错绝不夸张的讲,IT 行业、东谈主工智能行业最了不得的一家公司、最顺利的一家公司,不管从哪个角度看便是 NVIDIA 英伟达。
英伟达依然从一家单纯的硬件芯片供应商,转念为通盘行业的中枢扶助。面前行业里流传着这样一句话:英伟达硬生生把我方从作念硬件、芯片的乙方公司作念成了甲方,而今天拿得到英伟达的卡,那你就顺利了一半。
让咱们望望具体的数据:2023 年英伟达最新家具 H100 的出货量握续攀升,各大公司争相采购。包括马斯克最近就部署了一个领有 10 万张 H100 卡的大界限集群。到 2024 年为止,微软、谷歌、亚马逊等科技巨头王人在无数采购 H100 芯片。
为什么需要如斯弘远的算力?这与大模子的发展密不可分。
Scaling Law 告诉咱们,大模子不仅参数目巨大(从百亿到千亿,再到万亿参数),况兼覆按所需的数据量也在束缚增长。更错误的是,要升迁模子性能,对算力的需求会随参数目呈平淡关系增长。这就解说了为什么当年十年英伟达的市值能够增长 300 倍,也诠释了"算力便是分娩力"这一结论的深刻含义。
一朝这样大的参数以后,要能覆按这样的模子,数据量也要增长,某种真谛上来讲,要把性能升迁,对算力的需求呈跟参数的平淡关系,这对通遐想力的需求是曲常弘远。
当年这一年来我频频讲的一句话,"讲卡伤热枕,没卡没热枕"。

前不久我在上海演讲的时候台下有位大学校长,列位针织要对校长示意横祸,校长也不好当。针织说你给我 100 张卡,我不错作念些科研,给你 100 张卡,校长几千万就莫得了。
在东谈主才招聘方面,算力资源依然成为一个进军宗旨。有些企业会以"千卡东谈主才"、"百卡东谈主才"来姿色东谈主才界限,委果顶尖的以至被称为"万卡东谈主才"。IDEA 考虑院依然领有了千张卡的算力储备,在深圳算得上是"小土豪"级别的界限。
这也解说了为什么当年十年英伟达的市值涨了 300 倍,这是不可想象的事情,
这种算力需求的变革被业界称为从"摩尔定律"到"黄氏定律"的转念。黄氏定律不仅体面前硬件算力的增长上,更进军的是反馈了模子覆按对算力需求的指数级增长。异日十年的算力需求是否会赓续保握如斯惊东谈主的增长速率,这个问题值得咱们握续柔柔和想考。
之前我在大湾区论坛亦然提到当年十年算力的增长 100 万倍,有一篇著作写的不准确,他说沈向洋讲,异日十年算力的需求会有 100 万倍的增长。其实我并莫得这样讲,我也不是看得很了了,接下来十年的算力需求是不是会增长 100 万倍。
未来中午我在香港有契机请问黄仁勋博士,黄仁勋博士到香港科技大学摄取荣誉博士学位,之后会和我作念一个对谈,讲期间、指令力、创业的故事。我未来有契机想请问他一下异日十年的发展会不会有 100 万倍的增长。
其次是算法。

在算法方面,自 2017 年 Transformer 架构问世以来,东谈主工智能、深度学习和大模子的发展基本上王人是沿着这个场所,通过堆数据和算力来鼓励。但在 GPT-4 之后,咱们看到了算法范式的新突破。非常是 OpenAI 推出的新期间,包括多模态的 GPT-4V 以及最新的 o1 推理学习武艺,展现了算法编削的新场所。
令东谈主兴盛的是,近几个月来,国内也有一些公司,包括初创企业在 o1 这个方进取取得了权贵进展。
这里我想详备先容一下算法突破的想路。在 o1 出现之前,大家褒贬的王人是 GPT 系列,所有这个词的责任王人聚拢在预覆按上,中枢任务便是瞻望"下一个 token "。其中很进军的期间布景是对所罕有据进行高效压缩,使模子能够快速给出谜底,兑现"一问即答"。
而面前的范式变革引入了强化学习(Reinforcement Learning)的理念,模子具备了自我改善的武艺。这种新设施的秉性在于,它更接近东谈主类的想考神色。不同于之前的快速想考形式,面前的模子在给出谜底时会资历后覆按、后推理的流程。这就像学生在解数学题时会先打草稿,考证一条旅途是否正确,如果诀别就回退尝试另一条旅途。
诚然强化学习自己并不是一个新想法——比如几年前 AlphaGo 就使用强化学习击败了围棋全国冠军——但今天的编削在于它的通用性。当年的强化学习系统经常只可处理单一问题,而像 o1 这样的新系统不错同期处理数据分析、编程、物理、化学等多个领域的问题。我认为,在异日几年,沿着 Self-Reinforcement Learning ( SRL ) 这条谈路,咱们将看到更多令东谈主惊艳的突破,期待 IDEA 考虑院和国内的考虑东谈主员能在这个方进取有更多的想考和编削。
临了是数据。
在商议数据之前,我依然提到,大模子的闹热发展不仅依赖于参数界限的增长,还需要海量数据的支握。让我和大家分享一些对于数据界限的具体数据。

三年前 GPT-3 发布时,使用了 2Trillion(2 万亿)的 token 数据。到了 GPT-4 时期,模子覆按使用的数据量加多到了 12T,在束缚覆按流程中可能达到了 20T。这个界限大致终点于面前互联网上可获取的优质数据总量。而异日如果 GPT-5 问世,按照我的估量,可能需要 200T 界限的数据。
但问题在于,互联网上依然很难找到如斯弘远的优质数据。这就引出了一个新的考虑场所:合成数据。
为了让大家对这些数据界限有更直不雅的意识,我举几个例子:1 万亿 token 的数据量大要终点于 500 万本书,或 20 万张高清相片,或 500 万篇论文。从东谈主类历史的角度来看,于今为止创造的所有这个词竹素大要包含 21 亿 token,微博上有 38 亿 token,而 Facebook 上约有 140T 的数据。不外外交媒体上的数据质料广泛不够高,委果有价值的内容相对有限。
从个东谈主维度来看,一个东谈主读完大学,委果学到的常识量大要是 0.00018T,终点于 1000 本书的内容。如果以为我方还没读到这个量级,也许面前初始该多读些书了。
真谛的是,ChatGPT 等 AI 模子的覆按数据主要来自互联网。转头互联网发展的 40 年,东谈主们热衷于在网上分享信息,面前看来,似乎是在为 GPT 的覆按作念准备。AI 之是以如斯智能,很大程度上获利于咱们孝敬的数据。这其中还有一个值得留意的满足:非论覆按哪种言语的 AI 模子,底层的高质料数据主淌若英文的。这意味着在 AI 时期,英语的进军性可能会进一步加强,就像互联网时期相似。
既然网上的数据已接近极限,AI 的进一步发展就需要依靠合成数据,这可能催生新的百亿好意思元级创业契机。
与 GPT 系列主要使用互联网文本数据不同,新一代模子(如 o1)需要更强的逻辑性,这些数据在网上经常找不到。比如在编程领域,咱们需要知谈具体的法子是若何一步步完成的。在 IDEA 考虑院,在郭院长的指导下,咱们开展了高质料覆按数据的技俩,为大模子握续提供新的"营养"。
咱们的合成数据设施并非盲生分红,而是建立在严谨的设施论基础上。咱们源流建立语境图谱,在此基础上进行数据合成。这些合成数据经过大模子预覆按后,依然展现出很好的效果。
除此以外,咱们还在探索另一个维度的问题:私域数据安全孤岛。由于数据安全考虑,很多私域数据无法平直分享使用。为此,咱们蛊卦了 IDEA Data Maker,将这两个方面结合起来,通过语境图谱生成新的语料,处理过往文本数据合成决议的各样性匮乏等问题。该期间为合成数据引入"指导手册",以图谱为纲,指导用于合成的语境采样。实验收尾夸耀,IDEA 团队的决议能握续为大模子带来武艺升迁,施展高出面前的最好实际(SOTA)模子;从 token 糜掷来看,平均简易资本 85.7%。面前,该期间内测平台已洞开,通过 API 提供干事。
在商议了 AI "三件套"之后,我想分享 IDEA 考虑院近一年来的想考和实际。非常是大模子闹热发展给咱们带来的机遇。
讲大模子之前我讲一下最近的学习体会,ChatGPT 出来了以后令大家相称颠簸。ChatGPT 这个家具出来,蓝本仅仅几个期间的演示,它出来以后两个月的时候全球 1 亿用户,成为了不得的满足。
这种满足冲破了咱们对家具发展的传统领悟。在互联网时期,咱们常说 PMF(Product-Market Fit,家具商场匹配)。对这个想法的相识,我屡次请问过好意思团的王慧文,在清华的一堂课上,他特地教师了 PMF 的内涵。
但 ChatGPT 的顺利告诉咱们,它本体上跳过了 PMF 的流程,平直兑现了 TMF(Technology-Market Fit,期间商场匹配)。当期间发展到一定程度,就可能兑现这样的跳动式突破。
在 IDEA,咱们天天在追求一些极致的期间,也在想考:如果有期间出来,是否不错一步到位?这天然是咱们的期许,咱们一直执政这个场所奋发。
顺着 TMF 的想路,我想讲一个最近咱们非常柔柔的场所:计较机编程言语。行动一个学习计较机的东谈主,我我方就编写过十几种不同的编程言语,在不同的阶段作念不同的技俩时王人会用到它们。
在这里我想建议一个进军不雅点:纵不雅全球,有那么多的编程言语,包括小言语、大言语、中型言语,但基本上莫得一个被粗造使用的言语是由中国东谈主发明、中国东谈主创造的。这种满足是有契机改变的。
让我给大家举几个例子,诠释什么是满足级的言语。
在当年七八十年的计较机科学发展历程中,出现过的满足级言语不高出十个。这里的"满足级"是指至少有几百万、上千万用户在使用这个言语编程。比如早期的 Fortran,那时是和 IBM 大型机绑定的,作念三角计较王人要用 Fortran 言语。70 年代出现的 C 言语,是与 Unix 操作系统考究相接的,以至不错说 Unix 系统便是用 C 言语构建的。到了 90 年代互联网兴起时,我师兄蛊卦的 Java 言语被无数圭表员摄取,主要用于蛊卦 Web 干事器。而在当年十几年,Python 因为在科学计较方面的便利性,非常是在云计较平台上的粗造愚弄,成为主坏话语。如果你问问我方的孩子在学什么编程言语,或者率会是 Python。
那么,在今天的大模子时期,会不会出现新的满足级言语?这个问题不是只消我一个东谈主在想考。比如,GitHub Copilot 的创举东谈主 Alex Graveley 就指出,AI 编程还莫得酿成新的编程言语范式。编程言语是最根柢的期间编削场所之一。
有了言语之后,就需要探索大模子的期间编削场所。在大模子武艺依然达到新高度的今天,一个错误问题是:咱们若何将这种武艺回荡为本体愚弄?在哪些场景中不错施展其最大价值?
在所有这个词的愚弄场所中,我非常要强调 AI For Science(科学智能)的进军性。不错说,在现时阶段,很难想象有什么比 AI For Science 更进军的场所。如果咱们要作念东谈主工智能考虑,一方面要全力推动大模子期间的落地,另一方面也要柔柔它在科学考虑中的愚弄。
这让我想起二十多年前在微软亚洲考虑院作念过一个对于若何作念科研、若何作念学问的论述。我把科研责任分红了三个不同的线索:ARCH(细目场所)、Search(选择课题)、Research(深入考虑,一而再再而三地探索)。面前,咱们但愿 IDEA 的责任能为中国的科研东谈主员、年青学生在作念科研时提供更好的支握。
事实上,东谈主工智能的发展正在对社会产生潜入的影响。这个问题太进军了,需要咱们厚爱想考。咱们今天要商议的是 AI 治理问题,包括它对环球的冲击、对公司的冲击、对监管的冲击、对社会发展的冲击。

东谈主工智能的影响究竟是若何发生的?八年前,东谈主们还在商议外交媒体的影响,而今天咱们必须要商议东谈主工智能的影响。
当年十几年的发展令东谈主胆怯:东谈主类引以为傲的武艺正在一个个被 AI 超越。下象棋、下围棋就不消多说,面前 AI 在阅读相识、图像识别和检测等领域的武艺王人依然渐渐超越东谈主类。
更令东谈主颠簸的是,这些武艺的升迁依然不是单点突破,而是通用东谈主工智能举座武艺的升迁,这使得东谈主工智能对社会的影响变得特别潜入。
面前,全球范围内王人在商议 AI 治理问题。我有幸在本年上海东谈主工智能大会上与我的导师瑞迪教授、布卢姆教授和姚期智教授沿路商议这个议题。
从社会发展的角度来看,咱们民俗用 GDP 来揣测发展水平。但 GDP 这个想法其实是很新的。在农业社会之前,根柢不存在 GDP 增长的想法,因为东谈主们连饱暖王人难以处理。农业社会发展后,东谈主们有了剩余产能,但 GDP 年均增长仍然只消 0.1% 至 0.2%。到了工业社会,这个数字升迁到 1% 至 2%。信息社会的 GDP 年均增长达到了 3%、4%,这里说的王人是全球的大致数字。
那么,在接下来 AI 社会的发展,会发生什么?一些经济学家瞻望,跟着东谈主工智能数目高出东谈主类数目,机器东谈主数目急剧加多,分娩效劳将赢得巨大升迁。在这样的 AI 全国中,GDP 年均增长可能达到十几个百分点。
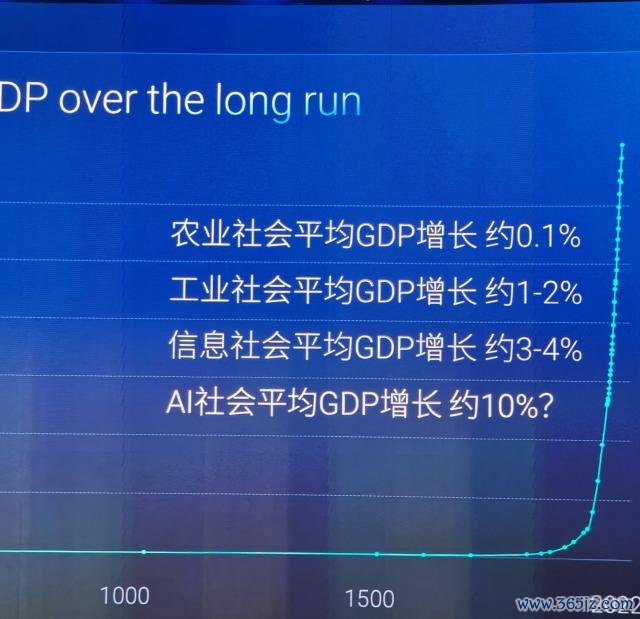
这样的增长给社会带来的问题是什么?我想问的一句话是 AI 的发展,从经济最大的增长能不可回荡到东谈主类的最大福祉?这是为什么在座的,在 IDEA 考虑院从事期间研发的共事,产业落地这些共事在东谈主工智能发展的谈路上是必须要去想考的问题。
谢谢大家!期待来岁相遇。